Category: Data Platforms
-

Snowflake ML Platform vs Custom Infrastructure: Why Most Don’t Need Custom
The $800K Platform You Probably Don’t Need I watched a Series B SaaS company spend $680K building a custom ML platform last year. Custom MLflow deployment. Airflow orchestration. Feature store built from scratch. The works. They had 2 data scientists and 20 models. The Snowflake ML platform would have handled everything for $180K. This isn’t…
-
A Review of Snowflake Snowpark
After spending several months using Snowflake Snowpark, I’m really impressed with how it enhances the data engineering and data science experience within the Snowflake ecosystem. Essentially, Snowpark allows you to write and execute code directly inside Snowflake using languages like Python, Scala, and Java. This eliminates the need for external processing engines, which reduces complexity…
-
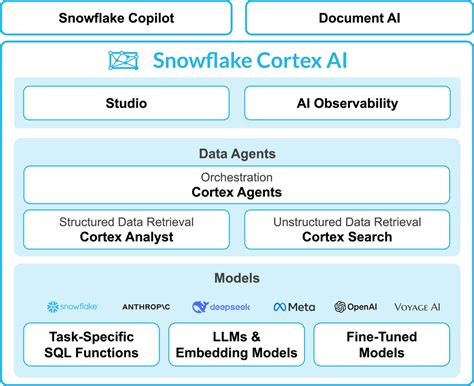
What’s the Deal with Snowflake Cortex AI?
Snowflake Cortex is basically Snowflake’s way of saying, “Hey, we do AI now!” It’s a fully managed service that brings machine learning and generative AI right into your Snowflake environment. So instead of shipping your data out to some other service for analysis, you can just do the smart stuff right there, right where your…
-

Snowflake Query Optimization: Tips for Faster Performance
Nobody likes slow queries – they’re the digital equivalent of waiting in line at the DMV. Let’s speed things up with some proven optimization techniques. The Low-Hanging Fruit: — FastSELECT customer_id, order_date, total_amount FROM large_table; Advanced Optimization Techniques: Use Clustering Keys for Large Tables: If you’re repeatedly filtering or joining on specific columns, clustering keys…
-
Your First 30 Days with Snowflake
Step-by-step guide to learning Snowflake in 30 days. From account setup to advanced features, with SQL examples, common mistakes to avoid, and practical exercises.
-

Snowflake Architecture Explained
Understand Snowflake architecture: storage-compute separation, multi-cluster warehouses, and cloud services with real performance insights.
-

Wrangling Data with Databricks Delta Live Tables
Implement the Medallion architecture (Bronze, Silver, Gold) using Databricks Delta Live Tables. Automate data pipelines with declarative transformations and built-in quality checks.
-
Migrating from Hive to Unity Catalog in Databricks
Migrate from Hive metastore to Unity Catalog in Databricks. Step-by-step guide to upgrading your data governance with unified access control and lineage tracking.
-
Data Warehousing with Hadoop
Almost from the moment Hadoop was first introduced, organizations have sought to replace their expensive data warehousing systems with it. Hadoop’s distributed nature and the fact that it uses commodity hardware make it cheap, massively scalable, and highly available. However, data warehousing with Hadoop is often ill-advised and the projects have ended badly. HDFS, the…
-

Using Seahorse for Spark on a Cloudera HA Cluster
I’m loving Seahorse, a GUI frontend for Spark by deepsense.io. The interface is simple, elegant, and beautiful, and has the potential to significantly speed up development on a machine learning workflow by its drag-and-drop nature. Thus far I haven’t run into any major bugs that affect the results so naturally that shoots it near the…